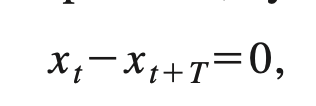
주기 T를 가진 신호 x를 가정하자.
이 신호에 대한 제곱을 구하여 평균을 내도 동일하게 0임


반대로 미분 함수를 통해서 주기를 알아낼수 있음. 당연하게 r이 0이면 주기임. 그리고 이 주기의 배수값만큼 값이 무한대 있음.

제곱합을 확장하여 ACF 형태로 표현할 수 있음(이해못함)
첫 두 항은 에너지 항. 두 항이 상수면 미분함수 d(r)은 r(r) 반대로 변하고, 둘중에 한쪽의 최대값을 구하면 반대쪽의 최소값을 구하는거랑 마찬가지임.
하지만 두번쨰 에너지 항도 r에 변해서, r(r)의 최대값과 d(r)의 최소값은 다를수 있음.
실제로 unbiased autocorrelation에서 오류율이 10퍼였게 difference function에서 1.95퍼로 낮아짐.
-- 생각 --
주기 = 1/f 이니까 pitch detection 알고리즘에서 주기를 구해서 pitch를 구한다. difference function에서 0인거를 구하면 주기가 나오니까, 거기서 음정을 구하는건가? 확인 필요
이렇게 확 변한게 놀라울수도 있는데, 식 1의 방법은 진폭 변화에 너무 예빈함. 시간이 지남에 따라 신호 진폭이증가하면 ACF 피크 진폭이 일정하게 유지되지 않고 lag와 함께 증가함. 이는 고차 피크를 선택하게 하고 "too low" error를 만듦.

too low, too high error가 정확히 무슨뜻인지는 모르겠음.. 고차 피크를 선택하는데 왜 too low?
다음 단계에서 이 에러들을 줄인다니까 일단 넘어감
식2가 진폭에 덜 예민한 함수를 만듦. 그러나 d(r) 사용하는 방식은 식 4의 신호 모델에 밀접하게 기반하고 있으며 "too low" 오류와 "too high" 에러를 잡기 위한 다음 두 오류 단계를 위한 기반을 마련함.
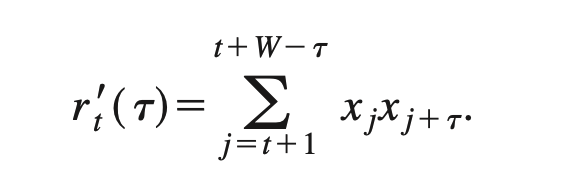
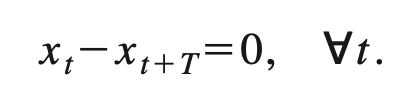
--생각--
식 4를 이용하는 방법이라, 이 후 나올 방법도 식 4를 사용하기 떄문에 기반이 된다는 의미인듯?
식2가 식1에 비해 진폭에 덜 예민한 이유는 무엇인가?

2로 계산하면 이렇기 때문.
lag가 커질수록 0에 근접해가는 이유는 큰 r일수록, 당연하게도 더 적은 term이 있기 때문(r이 크다는건 시간 지연이 많다 -> 찍히는 값이 적다
